Przeanalizujemy dane o pensjach, aby zrozumieć wzorce i korelacje między wiekiem, doświadczeniem a zarobkami. To kluczowy krok przed przejściem do Machine Learning.
Analiza obejmuje:
- Statystyki opisowe
- Rozkłady zmiennych
- Korelacje między cechami
- Identyfikacja wzorców
Statystyki opisowe danych:
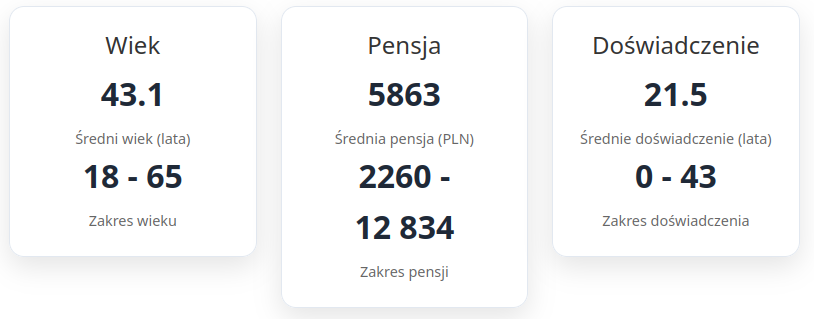
Kod Python – Analiza statystyczna:
# Analiza statystyczna
import pandas as pd
import numpy as np
# Statystyki opisowe
print("=== STATYSTYKI WIEKU ===")
print(f"Średni wiek: {df['wiek'].mean():.1f} lat")
print(f"Mediana wieku: {df['wiek'].median()} lat")
print(f"Min wiek: {df['wiek'].min()} lat")
print(f"Max wiek: {df['wiek'].max()} lat")
print("\n=== STATYSTYKI PENSJI ===")
print(f"Średnia pensja: {df['pensja'].mean():.0f} PLN")
print(f"Mediana pensji: {df['pensja'].median():.0f} PLN")
print(f"Min pensja: {df['pensja'].min():.0f} PLN")
print(f"Max pensja: {df['pensja'].max():.0f} PLN")
# Korelacje
correlation = df['wiek'].corr(df['pensja'])
print(f"\nKorelacja wiek-pensja: {correlation:.3f}")
Brak odpowiedzi